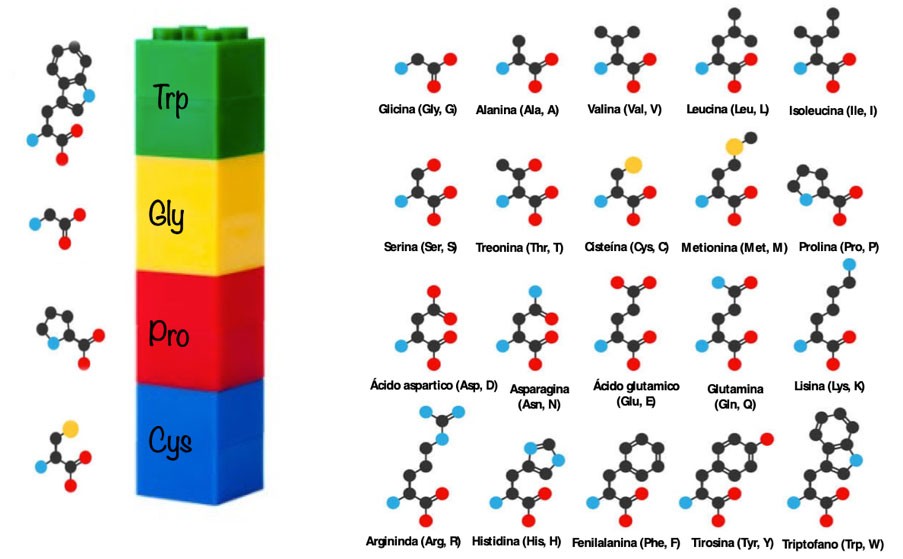
Imaginemos el diseño de péptidos como un proceso tan simple que consiste en apilar piezas de lego de distintos colores para formar una torre. En esta analogía, las piezas de lego serían equivalentes a las moléculas denominadas aminoácidos, las cuales se van apilando para dar lugar a una cadena de aminoácidos. Aquí es importante notar que el número de “colores” o tipo de aminoácidos que podemos utilizar está limitado a 20 (Figura 1), porque la naturaleza así lo dispuso. Cuando la cadena es corta, con menos de 50 aminoácidos, ésta ha de llamarse “péptido”, de lo contrario la cadena adquiere el nombre de proteína; aunque en realidad esta línea divisoria para clasificar cadenas de aminoácidos basada en el número de componentes es bastante borrosa y no tan clara como se podría pensar. En la vida real, la diversidad conformacional (geométrica) que la estructura de un péptido puede explorar es abrumadora, incluso el número de permutaciones que se pueden obtener al mutar (intercambiar) los aminoácidos de una cadena de 10 elementos, es del orden de 2010, tornándose el diseño de péptidos en un proceso bastante más complejo que en nuestra analogía inicial. Sin embargo, esta complejidad es a la vez un reto apasionante que nos puede llevar a mejorar diversos aspectos de la vida humana.
Un estimado reciente sugiere que alrededor del 40% de todos los enlaces en las redes de interacción de proteínas se deben a la unión de péptidos cortos de entre 3 y 10 aminoácidos de longitud a dominios de proteínas1, resaltando la importancia de las interacciones peptídicas. La unión de estos péptidos a proteínas desencadena una serie de eventos que pueden ser desde procesos fundamentales para la vida humana, hasta procesos que producen efectos tan perjudiciales que conducen a enfermedades mortales. Supongamos que conocemos un proceso en el cual un péptido X se une a la proteína Y, con lo cual se desencadena una serie de eventos que conlleva a cierta enfermedad, quisiéramos entonces diseñar un péptido A que compitiera con X para unirse a Y; si A logra evitar la unión X-Y, se evitaría el desarrollo de la enfermedad. Esta es la aplicación del diseño de un péptido para que actúe como inhibidor. Tal es el caso del péptido Enfuvirtida, la primera terapia de su clase para inhibir la entrada del VIH-1 a las células del hospedero2.
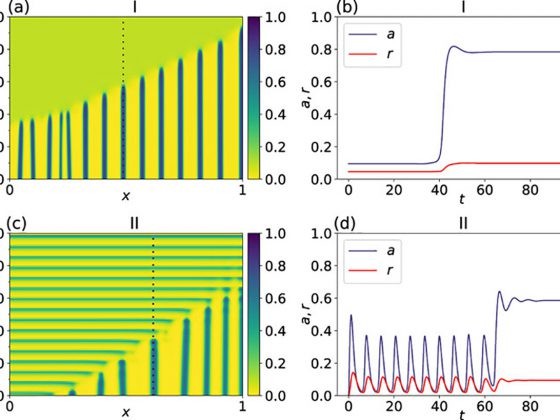
Otro ejemplo de aplicación es el diseño de péptidos para biosensores. Ejemplificando esto podríamos utilizar la analogía del pescador, en la cual se quiere capturar a un pez en específico (proteína de interés), esto se logra poniendo un anzuelo con una carnada apropiada (péptido adecuado), de tal manera que al capturar al pez, se tensará la caña de pescar (se generará una señal eléctrica, óptica, etcétera), y esto indicará al pescador que ha capturado a su presa e incluso dependiendo de la fuerza con la que se tense la caña de pescar, el pescador podrá inferir el tamaño de la presa (detección y medición de concentraciones de la proteína en la muestra). Por ello es deseable que el péptido diseñado para esta aplicación posea ciertas características particulares, como una alta afinidad (que las dos moléculas tiendan a unirse) y selectividad por la molécula objetivo (que prefieran unirse a ella y no a otras moléculas presentes en la muestra). Tal es el caso de los péptidos diseñados en nuestro trabajo más reciente2, donde la molécula objetivo es un biomarcador llamado resistina. La resistina y las proteínas de su misma familia han atraído la atención desde hace 20 años cuando fueron señaladas como un vínculo potencial entre la obesidad y la diabetes mellitus4, desde entonces, han sido asociadas con enfermedades inflamatorias, cardiovasculares y más recientemente con la severidad de la patología del COVID-19. Sin embargo, aún se ignora mucho sobre sus receptores (estructuras que desencadenan una respuesta al unirse a ella) y mecanismos de acción, por lo que su estudio promete resolver importantes incógnitas en la etiología de las enfermedades involucradas.
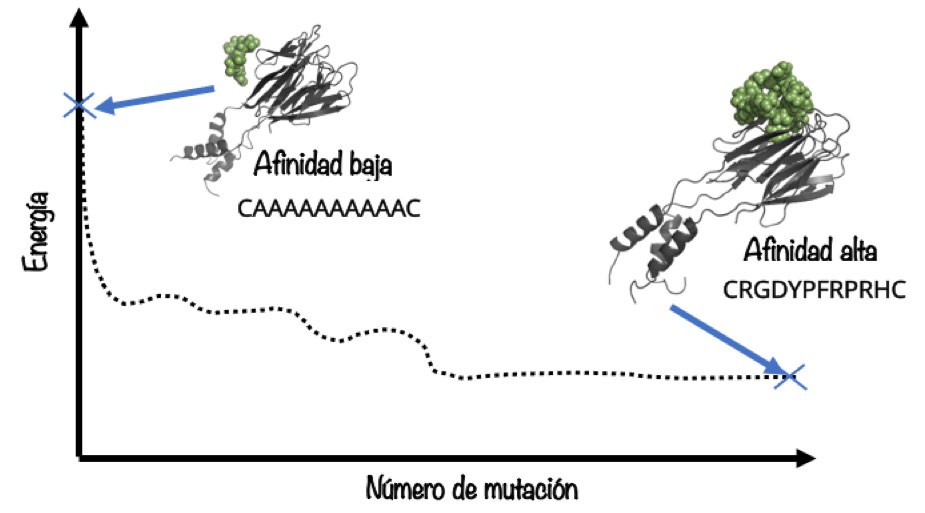
El diseño racional de proteínas y péptidos es un campo que se ha explorado mediante enfoques experimentales y computacionales. Cuando se dispone de información detallada de un sistema en particular, los métodos convencionales basados en el conocimiento proporcionan herramientas para el diseño de análogos más deseables. Sin embargo, la información detallada no siempre está disponible; es entonces cuando las herramientas computacionales ofrecen estrategias para un diseño “de Novo”, en el que se hace uso de principios y métodos físicos para crear nuevos péptidos o moléculas. Existen diferentes enfoques para abordar esta problemática por vía computacional: la inteligencia artificial nos ofrece las modernas herramientas de “machine learning” y “deep learning”; tenemos también algoritmos clásicos que se pueden usar para optimizar la secuencia y configuración de los péptidos de manera simultánea, con lo que se mejora la afinidad del péptido inicial por la proteína objetivo5. Esto se puede llevar a cabo en una serie de pasos de “mutación”, esto es, realizando en cada paso un intercambio al azar de un aminoácido en la secuencia del péptido, permitiendo luego que el péptido se acomode a la proteína y evaluando su energía de enlace, aceptando o rechazando la nueva secuencia y configuración de acuerdo a ciertos criterios (utilizando métodos Monte Carlo). Después de un número adecuado de pasos, se contará con un conjunto de péptidos afines a la proteína, dentro del cual se podrán seleccionar los que cumplan con otras características deseables como buena solubilidad en agua y selectividad por la proteína objetivo. La versatilidad de estos algoritmos es muy amplia y permite el diseño de péptidos para diferentes aplicaciones y necesidades como se ha demostrado anteriormente y se espera se siga ampliando el espectro de aplicación.
Referencias
1 Bhattacherjee, A., & Wallin, S. (2013). Exploring protein-peptide binding specificity through computational peptide screening. PLoS Comput Biol, 9(10), e1003277.
2 Matthews, T., Salgo, M., Greenberg, M., Chung, J., DeMasi, R., & Bolognesi, D. (2004). Enfuvirtide: the first therapy to inhibit the entry of HIV-1 into host CD4 lymphocytes. Nature reviews Drug discovery, 3(3), 215-225.
3 Chi, L. A., & Vargas, M. C. (2020). In silico design of peptides as potential ligands to resistin. Journal of molecular modeling, 26(5), 1-14.
4Steppan, C. M., Bailey, S. T., Bhat, S., Brown, E. J., Banerjee, R. R., Wright, C. M., … & Lazar, M. A. (2001). The hormone resistin links obesity to diabetes. Nature, 409(6818), 307-312.
5Hong Enriquez, R. P., Pavan, S., Benedetti, F., Tossi, A., Savoini, A., Berti, F., & Laio, A. (2012). Designing short peptides with high affinity for organic molecules: a combined docking, molecular dynamics, and Monte Carlo approach. Journal of chemical theory and computation, 8(3), 1121-1128.